
Refactoring is a common task for developers.. hopefully anyway. It keeps code cleaner, more maintainable, and reduces code duplication. It also allows for code to be extended more easily, saving us time in the long run.

There are many approaches we can take to refactoring as outlined by Martin Fowler's refactoring catalog. I'd wager that one of the most common refactoring approach is taking code that exists in multiple spots, wrapping it up in a method, and then calling that new method. Otherwise known as Extract Method.
To give an example, we're probably all familiar with something like the following..
public void MyMethod()
{
using (var file = new System.IO.StreamWriter(@"C:\log.txt"))
{
file.WriteLine($"Called { nameof(MyMethod) }");
}
}
public void AnotherMethod()
{
using (var file = new System.IO.StreamWriter(@"C:\log.txt"))
{
file.WriteLine($"Called { nameof(AnotherMethod) }");
}
}
Now, there are a couple problems with this implementation. Where the log is being stored to is explicitly defined in both of the methods. This could be problematic in the future if we decide to change the location and/or the file name of the log file.
The other problem is how we are logging is present in both methods. If we ever decided to create distributed logs, we would have to go into each method that called our logging functionality and update the call to StreamWriter to a network call.
Fear not though, we can refactor this approach and make our code a lot better. Applying the Extract Method refactoring gives us:
public void MyMethod()
{
WriteToDefaultLog($"Called { nameof(MyMethod) }");
}
public void AnotherMethod()
{
WriteToDefaultLog($"Called { nameof(AnotherMethod) }");
}
public void WriteToDefaultLog(string message)
{
using (var file = new System.IO.StreamWriter(@"C:\log.txt"))
{
file.WriteLine(message);
}
}
Now that all of the implementation details are put into a central location, and the dependent code snippets are calling the abstractions, it's a lot easier to introduce change into the system. This approach to refactoring is called Imperative Refactoring or "Inside out" refactoring.
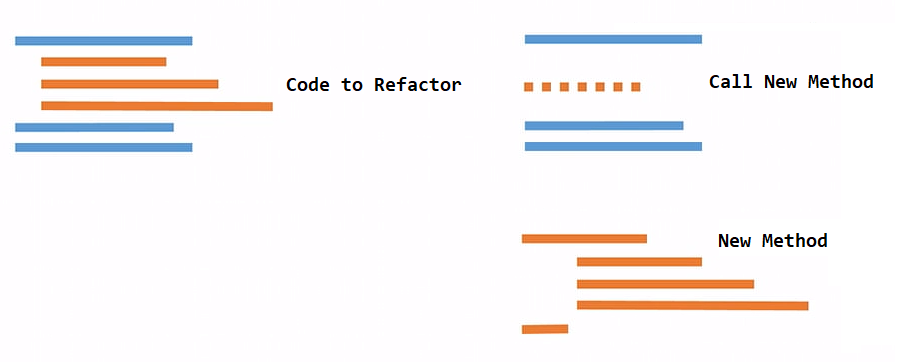
Visualized, we take the code in orange (the code to refactor), drop it all into a new method, somewhere in isolation. We then have the code call that new method, that abstraction we just created, instead of being intimately familiar with all of the implementation details. Pretty neat.
However, there is another approach to refactoring called Functional Refactoring or "Outside in". It is useful for when you want to refactor the surrounding code. Think of try/catch blocks or using blocks.
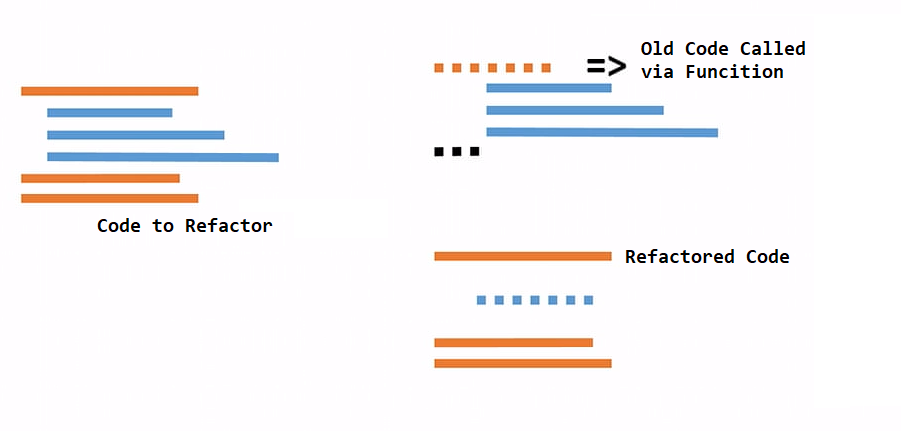
If that is not entirely clear, let's go ahead and look at some code.
Consider the following try/catch block that calls our default logger when a method throws an exception.
public void MyMethod()
{
try
{
SomeScaryStuff();
}
catch (Exception ex)
{
WriteToDefaultLog(ex);
}
}
public void AnotherMethod()
{
try
{
LessScaryButStillPrettyScary();
}
catch (Exception ex)
{
WriteToDefaultLog(ex);
}
}
So while the above may seem elegant and straightforward, we have some code duplication. We have explicitly written two try/catch blocks as well as called the same WriteToDefaultLog method. If we wanted to change that logging call, we'd have to update it in two spots.
This may not seem like such a big deal at first, but this could rapidly grow out of control if we wanted to call some logging functionality every time an error occurred in our application.
So how can we remove this duplication?
public static void Try(Action operation)
{
try
{
operation();
}
catch (Exception ex)
{
WriteToDefaultLog(ex);
}
}
By refactoring out the surrounding try/catch block, and passing in the inside code via an Action, we're able to create a new method, Try.
In order to leverage this method, the caller would need to pass in the code that they would want executed within the try block through a lambda expression.
public void MyMethod()
{
Try(() =>
{
SomeScaryStuff();
});
}
public void AnotherMethod()
{
Try(() =>
{
LessScaryStuffButStillPrettyScary();
});
}
With this approach we're able to encapsulate all of the logic that our try/catch blocks contain into a single location. Need to change the logging approach when an exception is thrown? No problem, we just need to update our Try method and we're good to go.
But wait, there's more! Consider the need to connect to a database through ADO. First you need to establish a connection to your database, and then you need to create a command to execute against that connection.
using(var connection = new SqlConnection("myConnectionString"))
{
using(var command = new SqlCommand("dbo.myCommand", connection)
{
// do some work
}
}
This is a pretty common setup, but has a couple drawbacks. First and foremost, it is verbose. The ceremony to call a procedure is multiple lines long. Secondly, if you ever needed to change how you retrieved your connection string... it'd be a sizable effort to update every procedure call. But there's hope! By applying some functional refactoring, we can abstract these implementation details away from the callers and make our procedure calls more succinct.
...
ExecuteCommand("dbo.myCommand", () => {
// do work
});
...
public void ExecuteCommand(string commandName, Action operation)
{
using(var connection = new SqlConnection("myConnectionString"))
{
using(var command = new SqlCommand("dbo.myCommand", connection)
{
operation();
}
}
}
As we can see, this approach can be applied to a lot of different scenarios. Logic and implementation details are hiding everywhere!, so don't always think Inside out... try Outside in!